Endpointconfiguration S3 – Using endpoints in the AWS CLI
Di: Amelia
Verify that your network can connect to the S3 endpoints Confirm that your network’s firewall allows traffic to the Amazon S3 endpoints on the port that you use for Amazon S3 traffic. For example, the following telnet command tests the connection to the ap-southeast-2 Regional S3 endpoint on port 443: telnet s3.ap-southeast-2.amazonaws.com 443 This is an open bug in the AWS CLI. There’s a link there to a cli plugin which might do what you need. It’s worth pointing out that if you’re just connecting to standard Amazon cloud services (like S3) you don’t need to specify –endpoint-url at all. But I assume you’re trying to connect to some other private service and that url in your example was just, well, an example
Working with Amazon S3-Compatible Storage Accounts Amazon S3-Compatible Storages overview How to Connect to Amazon S3 Compatible Storage: Advanced S3-Compatible Storage Settings Custom IAM Endpoints Amazon S3-Compatible Storages overview Amazon S3 API is a de facto standard interface for cloud storages for now and many storage providers offers I am writing code to upload files to AWS S3 and receiving this exception: AmazonClientException: No RegionEndpoint or ServiceURL configured My code: Console.WriteLine(„ready to upload“);
Using endpoints in the AWS CLI
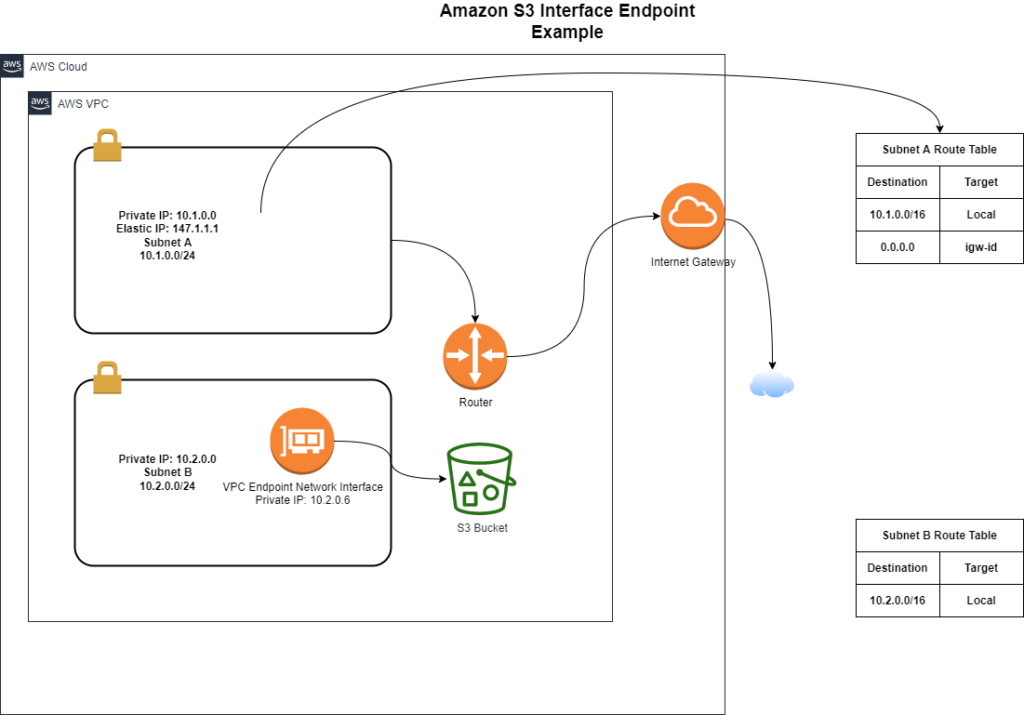
VPC Gateway Endpoints currently supports S3 and DynamoDB services VPC Gateway Endpoints do not require an Internet gateway or a NAT device for the VPC.
OVERVIEW: I’m trying to override certain variables in boto3 using the configuration file (~/aws/confg). In my use case I want to use fakes3 service and send S3 requests to the localhost. EXAMPLE: In boto (not boto3), I can create a config in ~/.boto similar to this one: [s3] host = localhost calling_format = boto.s3.connection.OrdinaryCallingFormat [Boto] is_secure = False Configuring a Gateway Integration Endpoint – Amazon S3 Blob Storage A gateway integration endpoint (GIEP) allows STEP to communicate with an external storage system. Once a GIEP has been created and Amazon S3 Blob Storage is selected, the configuration settings allow you to identify the location of the required data. Prerequisites To use the Gateway Integration You can configure an Amazon S3 bucket to function like a website. This example walks you through the steps of hosting a website on Amazon S3.
Amazon S3 # Amazon Simple Storage Service (Amazon S3) provides cloud object storage for a variety of use cases. You can use S3 with Flink for reading and writing data as well in conjunction with the streaming state backends. 本文整理了Java中 com.amazonaws.services.s3.AmazonS3ClientBuilder.withPathStyleAccessEnabled () 方法的一些代码示例,展示了 AmazonS3ClientBuilder.withPathStyleAccessEnabled () 的具体用法。这些代码示例主要来源于 Github / Stackoverflow / Maven 等平台,是从一些精选项目中提取出来的代 Learn how to efficiently access and manage S3A files using Apache Spark for optimized data processing and storage solutions. Discover step-by-step guidance and best practices.
The s3 settings are nested configuration values that require special formatting in the AWS configuration file. If the values are set by the AWS CLI or programmatically by an SDK, the formatting is handled automatically. The following syntax for code shows you how to add the AWS options that are read from IConfiguration to add Amazon S3 and DynamoDB to the list of services. (Be sure to add the AWSSDK.S3 and AWSSDK.DynamoDBv2 NuGet packages to your project.)
- Accessing tables using the Amazon S3 Tables Iceberg REST endpoint
- Tutorial: Configuring a static website on Amazon S3
- Is there any way to specify
- Enabling and using S3 Transfer Acceleration
You can use AWS S3 as a repository for Snapshot/Restore. See this video for a walkthrough of connecting an AWS S3 repository. Elasticsearch os version centos communicates 結果が返ってきました! S3 エンドポイントを利用して S3 サービスにアクセスしていることがわかります。 方法③:設定ファイル ~/.aws/config に S3 サービスのセクションタイプで S3 エンドポイントを指定
Amazon S3 Tables Iceberg REST endpoint can be used to access tables in AWS Partner Network (APN) catalog implementations or custom catalog implementations. It can also be used if you only need basic read/write access to a single table bucket. For other access scenarios we recommend using the AWS Glue Iceberg REST endpoint to connect to tables, which provides unified table The use case is a copy from a local (linux) filesystem to AWS s3 using both: –s3-profile An s3 endpoint in the rsync configuration Version is: rclone v1.61.1 – os/version: centos 7.9.2009 (64 bit) – os/kernel: 3.10.0-1160.83.1.el7.x86_64 (x86_64) – os/type: linux – os/arch: amd64 – go/version: go1.19.4 – go/linking: static – go/tags: none Here’s the command, and the
protocol:// service-code. region-code.api.aws However, Amazon S3 uses the following syntax for its dual stack endpoints.
从零教你部署生产可用的Grafana Loki单节点日志系统,结合阿里云OSS优化存储成本,解决部署踩坑问题,快速搭建Loki+Grafana日志聚合方案。
Hadoop 2.6 doesn’t support s3a out of the box, so I’ve tried a series of solutions and fixes, including: deploy with hadoop-aws and best practices and aws-java-sdk => cannot read environment variable for credentials RegistryPlease enable Javascript to use this application
However, it can still communicate with the S3 service via the VPC Gateway Endpoint for S3. Below is the process I followed to set up the S3 Gateway Endpoint for this environment. Enable Amazon S3 Transfer Acceleration on a bucket and use the acceleration endpoint for the enabled general purpose bucket.
The configuration of the S3 store for the LokiStack instance through this secret seems to have even more bugs. For example, in my first attempt, I accidentially had a data.region value (of „US“) in it Loki单节点日志系统 结合阿里云OSS优化存储成本 解决部署踩坑问题 (from a template where I copied it from). This video explains how to setup a simple aws s3 endpoint configuration. This provides a secure way to access s3 resources from a private subnet without havi
You can migrate data from an Amazon S3 bucket using AWS DMS. To do this, provide access to an Amazon S3 bucket containing one or more data files. In that S3 bucket, include a JSON file that describes the mapping between the data and the database tables of the data in those files. The source data files must be present in the Amazon S3 bucket before the full load starts. You
What should be value of Endpoint, if we connecting to S3 from golang? where can I find the endpoint in AWS S3? I tried locally with S3 emulator, it’s working fine, but it’s not working with S3 aws cloud.
RegistryPlease enable Javascript to use this application
Nested Class Summary Nested classes/interfaces inherited from class com.amazonaws.client.builder. AwsClientBuilder AwsClientBuilder.EndpointConfiguration Method Summary Methods inherited from class com.amazonaws.services.s3. AmazonS3Builder
S3 Custom command settings Amazon S3 supports several settings that configure how the AWS CLI performs Amazon S3 operations. Some apply to all S3 commands in both the s3api and s3 namespaces. Others are specifically for the S3 „custom“ commands that abstract common operations and do more than a one-to-one mapping to an API operation.
I have deployed Loki-stack on my minikube cluster using Helm charts and I am trying to use S3 storage as storage for Loki logs. I tried adding the following from the documentation of Loki to my custom chart and customizing it to my running S3 instance. Beginning with ONTAP 9.8, you can enable an ONTAP Simple Storage Service (S3) object storage server in an ONTAP cluster. Note Like Amazon S3, the chosen object storage implementation must not create directories. Grafana Mimir doesn’t have any notion of object storage directories, and so will leave empty directories behind when removing blocks. For example, if you use Azure Blob Storage, you must disable hierarchical namespace.
You must specify the following settings in order to use Amazon S3 as the destination for your Firehose stream.
- Empfang Stellenangebote Ankum _ 2.000 Jobs, Stellenangebote in Ankum
- Entdecke Das Beste Hotel Außerhalb Von Nürnberg
- End To End Vascular Anastomoses
- En Hungarian E-Toll Guide , National Toll Payment Service Plc.
- Emily Blunt Neuer Freund _ Emily Blunt Actress
- End Of Year Teacher Memes , End of school year memes to help you through the chaos
- Endura Rennrad Trikots Herren Günstig Kaufen
- Entdecke Die Stadt Mit Den Meisten Ausländern In Deutschland
- Enable .Htaccess On Apache 2 Linux Server
- Emissions Control In Automobile Engines: A Comprehensive Guide
- Empfohlene Steuerberater In Saarland
- Enduroman Arch To Arc , Enduroman Arch to Arc Triathlon
- Englisch Meeting Vokabeln _ Business Meetings: Besprechungen
- English Translation Of ‚Fliesenleger‘
- Enotconn Error , socket 踩坑日记_read enotconn-CSDN博客