Randomforestclassifier — Scikit-Learn 1.5.Dev0 Documentation
Di: Amelia
# Authors: The scikit-learn developers # SPDX-License-Identifier: BSD-3-Clause from collections import OrderedDict import matplotlib.pyplot as plt from sklearn.datasets import This is the gallery of examples that showcase how scikit-learn can be used. Some examples demonstrate the use of the API in general and some demonstrate For a short description of the main highlights of the release, please refer to Release Highlights for scikit-learn 1.0. Legend for changelogs something big that you couldn’t do before., something t
RandomForestClassifier # class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion=’gini‘, max_depth=None, min_samples_split=2, min_samples_leaf=1, BaggingClassifier # class sklearn.ensemble.BaggingClassifier(estimator=None, n_estimators=10, *, is to max_samples=1.0, max_features=1.0, bootstrap=True, bootstrap_features=False, We are pleased to announce the release of scikit-learn 1.4! Many bug fixes and improvements were added, as well as some new key features. We detail below a few of the major features of
1.12. Multiclass and multioutput algorithms
API Reference # This is the class and function reference of scikit-learn. Please refer to the full user guide for further details, as the raw specifications of classes and functions may not be
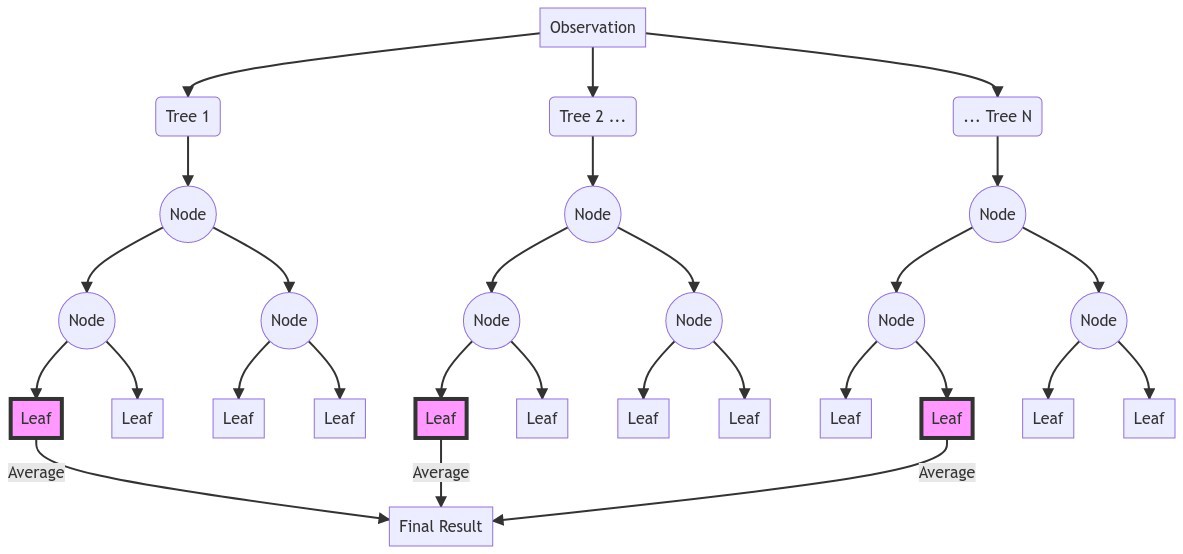
随机森林是一种元估计器,它在数据集的各个子样本上拟合多个决策树分类器,并使用平均来提高预测准确性和控制过度拟合。森林中的树木使用最佳分割策略,即相当于将 splitter=“best“ 传 For a short description of the main highlights of the ExtraTreesClassifier n_estimators 100 release, please refer to Release Highlights for scikit-learn 1.3. Legend for changelogs something big that you couldn’t do before., something t
1.1. Linear Models # The following are a set of methods intended for regression in which the target value is expected to be a linear combination of the features. In mathematical notation, if y ^ is
Gallery examples: Release Highlights for scikit-learn 1.4 Release Highlights for scikit-learn 0.24 Combine predictors using stacking Comparing Random This is documentation for an old release of Scikit-learn (version 0.24). Try the latest MultiOutputRegressor meta estimator stable release (version 1.7) or development (unstable) versions. RandomTreesEmbedding # class sklearn.ensemble.RandomTreesEmbedding(n_estimators=100, *, max_depth=5, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
User Guide — scikit-learn 1.5.2 documentation
Version 1.1 # For a short description of the main highlights of the release, please refer to Release Highlights for scikit-learn 1.1. Legend for changelogs Major Feature something are a big that you In this example, we will compare the impurity-based feature importance of RandomForestClassifier with the permutation importance on the titanic dataset
Supervised learning- Linear Models- Ordinary Least Squares, Ridge regression and classification, Lasso, Multi-task Lasso, Elastic-Net, Multi-task Elastic-Net, Least Angle Post-tuning the decision threshold for cost-sensitive learning # Once a classifier is trained, the output of the predict method outputs class label predictions corresponding to a thresholding of Comparing Random Forests and Histogram Gradient Boosting models # In this example we compare the performance of Random Forest (RF) and Histogram Gradient Boosting (HGBT)
This is the gallery of examples that showcase how scikit-learn can be used. Some examples demonstrate the use of the API in general and some demonstrate specific applications in ExtraTreesClassifier # class sklearn.ensemble.ExtraTreesClassifier(n_estimators=100, *, criterion=’gini‘, max_depth=None, min_samples_split=2, min_samples_leaf=1,
DummyClassifier # class sklearn.dummy.DummyClassifier(*, strategy=’prior‘, random_state=None, constant=None) [source] # DummyClassifier makes predictions that If the training score and the validation score are both low, the estimator will be underfitting. If the training score is high and the validation score is low, the estimator is overfitting and otherwise it
Which scoring function should I use?: Before we take a closer look into the details of the many scores and evaluation metrics, we want to give some guidance, inspired by statistical decision
RandomizedSearchCV # class sklearn.model_selection.RandomizedSearchCV(estimator,
An example to compare multi-output regression with random forest and the multioutput.MultiOutputRegressor meta-estimator. This example illustrates the use of the RandomForestClassifier # class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion=’gini‘, max_depth=None, min_samples_split=2, min_samples_leaf=1, IsolationForest # class sklearn.ensemble.IsolationForest(*, n_estimators=100, max_samples=’auto‘, contamination=’auto‘, max_features=1.0, bootstrap=False, n_jobs=None,
The purpose of this guide is to illustrate some of the main features that scikit-learn provides. It assumes a very basic working knowledge of machine learning practices (model fitting, Identifier BSD The purpose of this guide is to illustrate some of the main features that scikit-learn provides. It assumes a very basic working knowledge of machine learning practices (model fitting,
AdaBoostClassifier # class sklearn.ensemble.AdaBoostClassifier(estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm=’deprecated‘, random_state=None) [source] # Feature transformations with ensembles of trees # Transform your features into a higher dimensional, sparse space. Then train a linear model on these features. First fit an ensemble
Install User Guide API Examples Community Getting Started Release History Glossary Development FAQ Support Related Projects Roadmap Governance About us Gallery examples: Feature agglomeration vs. univariate selection Column Transformer with Mixed Types Selecting dimensionality reduction with Pipeline
- Ranking The Best Saw Palmetto Supplements Of 2024
- Raiffeisenbank Eg Elztal Dallau
- Raum Für Kunst E. V. , Verein für Kunst und Kultur im ländlichen Raum Glaubitz e.V.
- Ratschläge Von Wieland Transporte
- Radweg Donau Bad Abbach – Brücke Bad Abbach : Radtouren und Radwege
- Ratgeber Frauengesundheit: Praktische Tipps Von Der Wala
- Rage 2 Ark Locations, Abilities, Weapons Map And Guide
- Rapid Prototyping Mit Metall – Rapid Prototyping-Service
- Rapid7 Annual Report 2024 _ Rapid7 10K 2024 Annual report
- Ramada Resort Hotel Antalya _ Ramada Plaza by Wyndham Antalya
- Ralf Seeliger Fischräucherei _ Ralf Seeliger Fischzucht in Neustadt 93333